

December 13 update: ArXiv paper.
Claude Shannon was an amazing scientist. He is mostly known for his contributions in information theory, in particular Shannon entropy. Maybe in a time where chess has become popular in particular through the marvelous Queen’s Gambit miniseries, one also should mention that Shannon also wrote one of the first pioneering papers on computer chess. I myself get reminded about Shannon all the time as we live close to his home at the Mystic lakes a place I frequently run around. His estate, the Entropy house of course still stands and was recently renovated (it is a private residence however and is not a museum). A less known quantity introduced by Shannon is the Shannon Capacity. Similarly as Kolmogorov-Sinai entropy measures the exponential growth rate of errors in a dynamical system the Shannon capacity measures the exponential growth of the capacity of a communication channel with prescribed errors if one uses more and more redundant independent channels. One would think that the information capacity of Shannon is multiplicative but already Shannon computed it for an alphabet with 5 letters in which errors can occur cyclically. In that case the one gets not 2 as one would expect but the square root of 5 which is slightly bigger. Shannon himself estimated in that case the value to be between 2 and 2.5. For an alphabet with 7 letters and errors again possible in a cyclic way one does not know the capacity yet! I myself love these type of seemingly simple problems which are unexpectedly damn hard. The entropy problem for dynamical systems on which I worked for a decade with little success is such an example. Number theory problems about primes or factorization are other examples. The Shannon capacity problem is equally beautiful and known to be hard. There are actual mathematical reasons why the general problem must be hard since computing the independence numbers of graphs is a NP hard problem (this is because after dualizing the graph complement, one gets the clique problem which is one of the prototypical NP hard problems). Finding the Shannon capacity is even harder as we need to compute the independence number in a limit of larger and larger networks. So, this not only might be computationally hard but maybe even impossible to determine in general. Difficult problems need not to be difficult for subclasses however The entropy problem for dynamical systems is easy for example for group translations or some subshifts of finite type. The Hamilton path problem for graphs is difficult in general but easy for combinatorial manifolds which are all Hamiltonian, independent how large they are, the reason being that we can explicitly construct Hamiltonian paths for such manifolds. We will just see that one can compute the Shannon capacity of a class of networks quite easily.
Finite simple graphs can be multiplied by taking the Cartesian product of the vertex set and connect to points if the projection to both graphs is either a vertex or edge. We can therefore form the n’th power 


| Theorem: For a connection graph of a simplicial complex G with m zero dimensional points, the Shannon capacity is exactly m. |
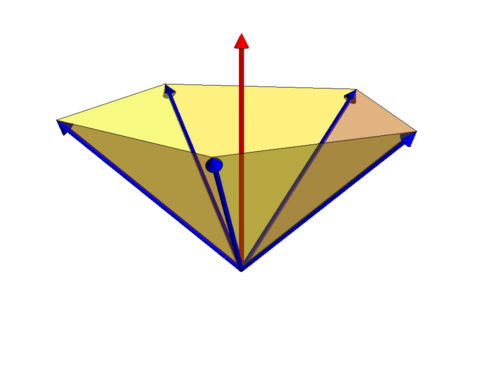 |
For a sketch of the proof and a bit more other things, see this youtube presentation. The lower bound on the Shannon capacity is the independence set, which is m. To get the upper bound we construct a “Lovasz umbrella” in 
![[1,1,1,\dots,1]/\sqrt{n}](https://s0.wp.com/latex.php?latex=%5B1%2C1%2C1%2C%5Cdots%2C1%5D%2F%5Csqrt%7Bn%7D&bg=ffffff&fg=000000&s=0 "[1,1,1,\dots,1]/\sqrt{n}")
_j = 1")
_j=0")

