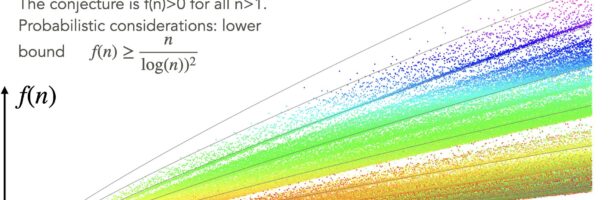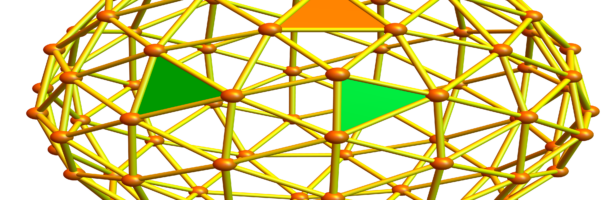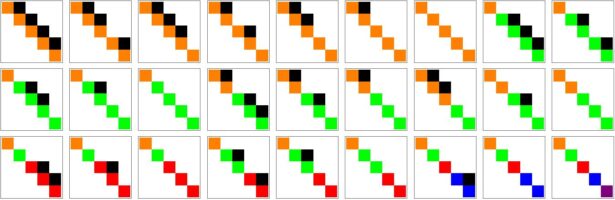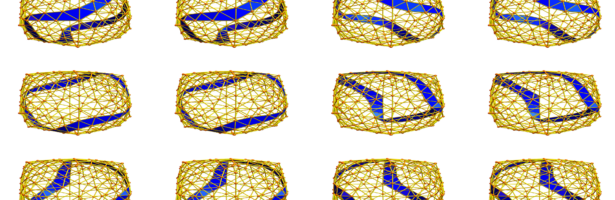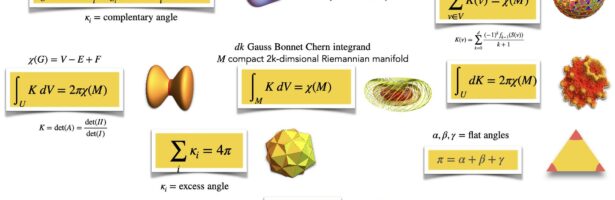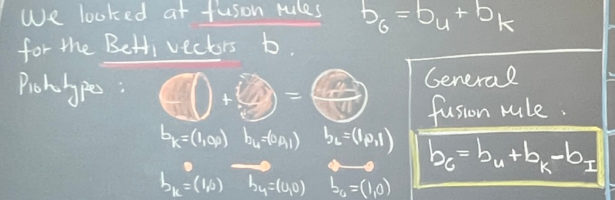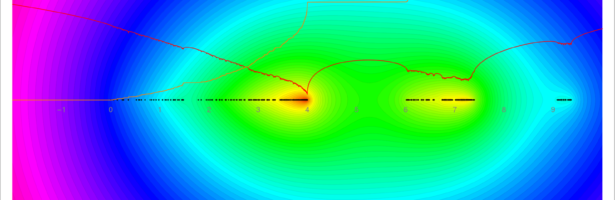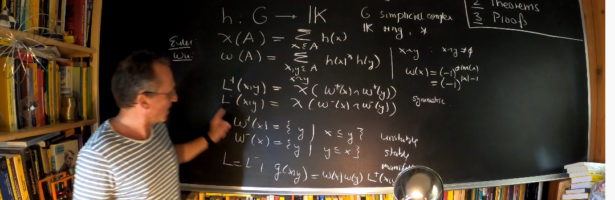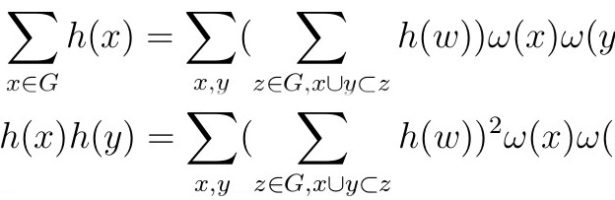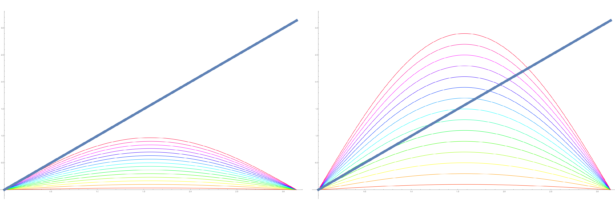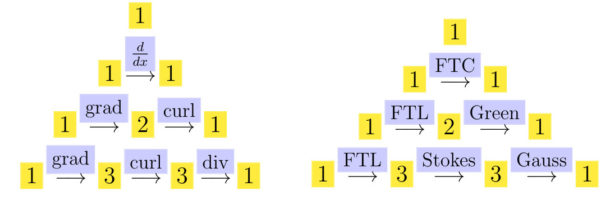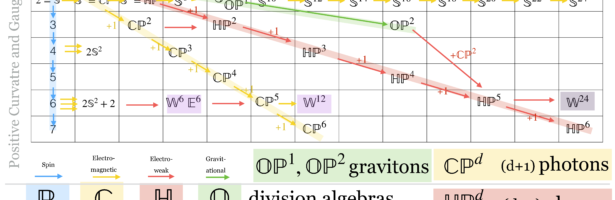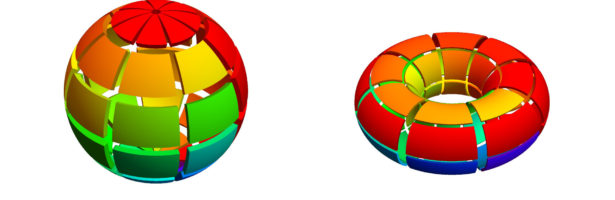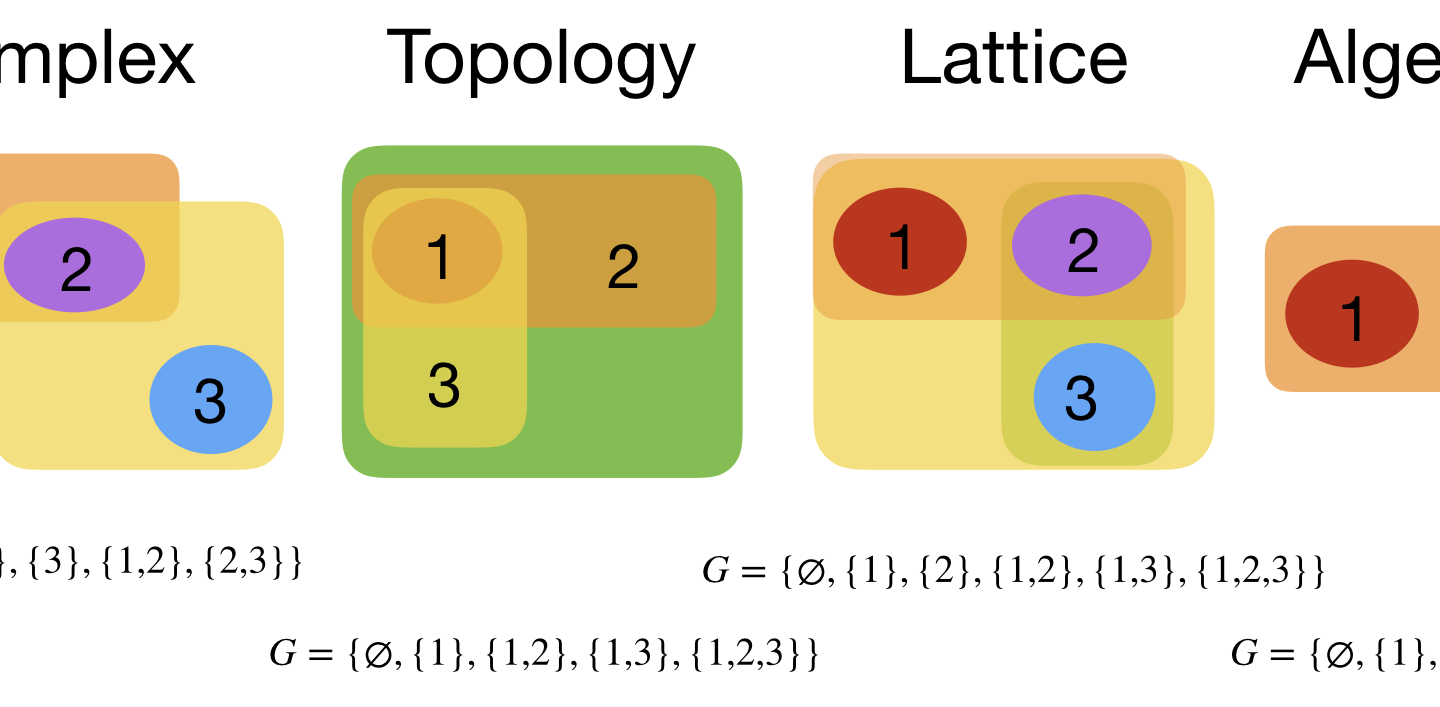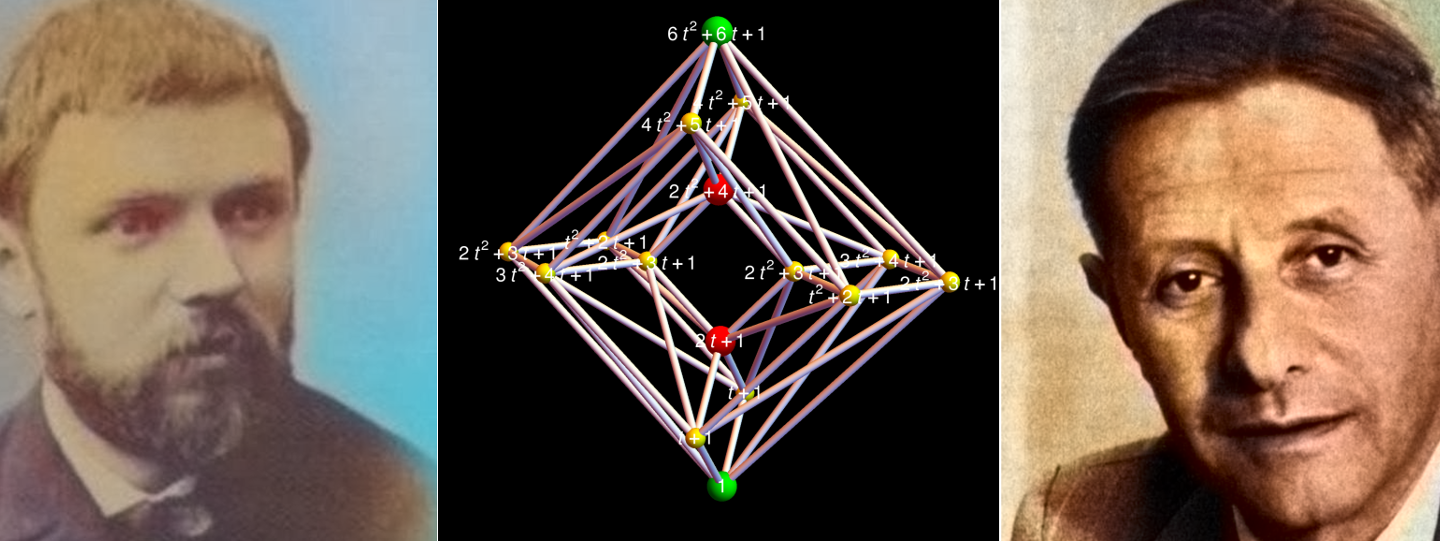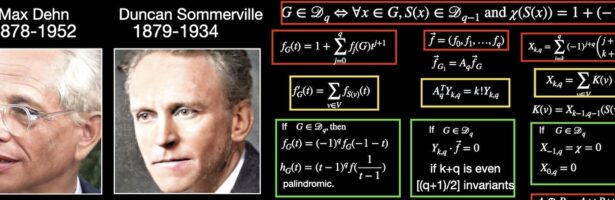
Dehn Sommerville Mindmap
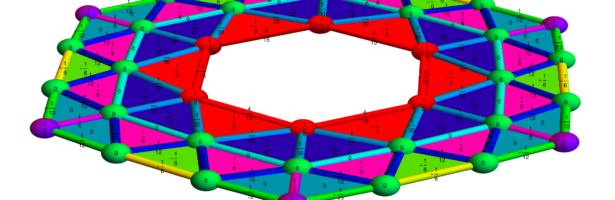
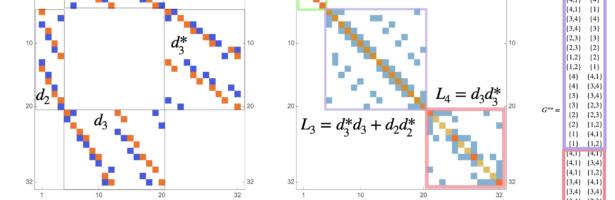
Next week, I will be back in my office. As they are constructing labs just near my temporay office, I made this “talk to myself session” in a seminar room of the department. I try to finish these days a review about Dehn-Sommerville, a rather unpopular topic historically speaking (not …